
Generative AI World
Source: Link here
Data sits at the heart of AI algorithms fueling technological advancements and has become part of our everyday lives. The success of various data-driven applications hinges on the input data quality to ascertain the level of trust a user can place in their output.
But you must be thinking that data quality is not something new. Indeed, it is an age-old problem plaguing the data industry, with the cost of bad-quality data running into trillions of dollars. Alarming right?
But the magnitude of the consequences has risen significantly, particularly in the world of Generative AI (GenAI).
But what is GenAI? As quoted by IBM research, “GenAI refers to deep-learning models that can generate high-quality text, images, and other content based on the data they were trained on.”
As we talk about GenAI, the discussion on Large Language Models (LLMs) becomes inevitable. LLMs, like the GPT-4 architecture that powers ChatGPT, are examples of generative AI. They are trained on enormous amounts of text from the internet, books, articles, and other sources to learn the statistical patterns and structures of language.
They have pivoted the AI landscape, highlighting the importance of good-quality data like never before. Be it the everyday chatbots or advanced applications integrating LLMs, data quality has gained unprecedented emphasis. It has become table stakes for organizations looking to leverage the power of GenAI and hence is the focus of our blog.
Bad quality data impacting LLM training
One of the reasons behind the ‘largeness’ of LLMs is that they are trained on a large corpus of data collected from various sources. The model relies on the quality of such big data to learn the complexities surrounding language patterns and generate coherent responses accordingly.
However, bad quality data in the form of inaccuracies or erroneous data records tend to introduce noise into the model training, which is very harmful. This noisy data hinders the model’s ability to comprehend and generate accurate and meaningful context, impacting its output quality.
More data, more chaos
By the very construct of the machine learning process, the models are shown numerous examples to generalize on new and unseen data. Similarly, LLMs learn from the underlying patterns in language data to generate text-based responses to different inputs.
But if the model has seen bad quality data, it fails to understand or respond appropriately to certain inputs or generates nonsensical or misleading answers. This can erode user trust and limit the model’s practical usefulness — a concern that you would frequently hear in the AI community.
Cost of bad data is way too high for LLMs
By now, we have come to grasp the substantial impact of bad-quality data on the pattern-learning process and reliability of LLMs. However, what is even more worrisome is the accompanying cost that arises when such data infiltrates the training of LLM models.
Let us explore why this cost is a matter of concern.
The training of these large models is known to require significant computing resources and energy. It becomes imperative, therefore, not to expend energy by letting the model learn from noisy or erroneous records.
Furthermore, it is not just restricted to the utilization of computational resources. The iterative nature of this process results in significant time delays in building the model, which subsequently contributes to the overall cost of model development.
To put the cost scale in perspective, a 530-billion parameter model would cost ~$100 M in retraining. Certainly, no one would want to spend such an exorbitant cost for letting the bad quality data slip by.
Data quality validation and verification are critical for building successful machine-learning models. However, when it specifically comes to training LLMs, the impact of poor data quality increases substantially due to the scale and complexity of the training process, making it all the more important to understand the significant adverse effects that can arise.
OpenAI has also voiced concerns about making the model forget the bad data, echoing the role of quality data.
Practice “Shift-Left”
Implementing data monitoring checks right at the source level is not only a best practice but also a proactive approach to preserving data quality. It acts as a cost-saving measure, eliminating the need for model retraining caused by data quality concerns that may arise later.
Addressing these concerns early on can minimize the need for costly model retraining. The longer data quality issues persist, the more costly they become for an organization. To mitigate this, it is crucial to shift the focus of data quality away from downstream consumers and towards its origin, adopting a “shift-left” approach.
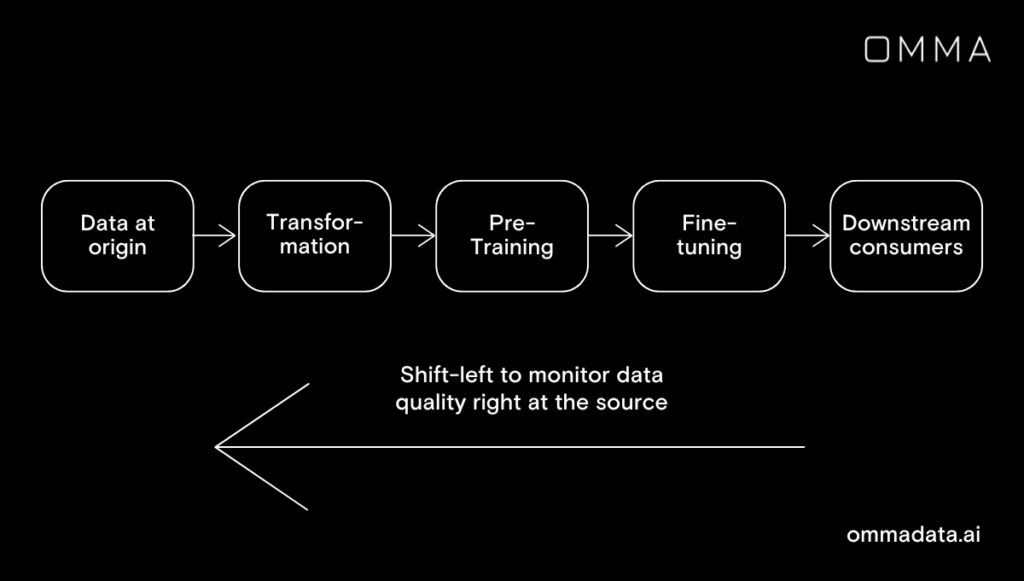
Monitoring data that drive model training
In addition to the tangible cost, the delay in acting on data quality involves an overhead of human oversight, which is responsible for assessing and validating the model results and providing feedback to improve the model performance. Inevitably, a lot of time is lost before these concerns are addressed through this feedback loop.
One does not get good data by default — one must create it
An ideal scenario would be to model the phenomenon or learn the pattern from well-curated data, but we do not get ideal data in the real world. So, let’s move into a realistic world where the data can have practically all sorts of issues and needs attention all across its multiple dimensions, such as accuracy, reliability, completeness, relevancy, etc.
It requires extensive data pre-processing such as duplicate removal, spelling and grammar correction, outlier detection, and filtering irrelevant or low-quality content. Analyzing data in greater detail includes checks including but not limited to identifying — what values a field can entail, the expected data types, what the schema looks like, the definition of an outlier record, etc.
The data changes shape and form at every handshake and requires an assessment of intended vs. actual data transformation. There exist various rules encompassing business knowledge, data distributions, field types, etc., alongside the best practices to implement them effectively.
While some static rules are certainly good, they quickly hit the limitation when dealing with large-scale data to train LLMs. Further, it is important to highlight that manual monitoring is prone to human errors, giving rise to the need for automated quality checks at scale.
Moreover, such automated checks alert the stakeholders in real-time, which facilitates continuous monitoring and correction — making it a lifecycle approach as against a one-time “fix-it-all” initiative.
Summary
The key concern among executives is the lack of trust in the data on which the insights are based. LLMs are already expensive to train in the first place, and the need to retrain arising from the bad-quality data would be nothing short of a nightmare. So, it’s imperative to work on all aspects of data quality to uncover the potential of LLMs and machine learning models.
To improve the return on investment (ROI) for any data initiative, irrespective of the size of datasets that power GenAI models, a thorough assessment of data quality are an absolute must.

