
Inteligencia Artificial Generativa
Los datos están en el centro de los algoritmos de IA que impulsan los avances tecnológicos y se han convertido en parte de nuestra vida cotidiana. El éxito de las aplicaciones impulsadas por datos depende de la calidad de los datos de entrada para determinar el nivel de confianza que un usuario puede depositar en sus resultados.
Seguro que estás pensando que la calidad de los datos no es algo nuevo. De hecho, es un problema antiguo para la industria de los datos, con un costo de datos de mala calidad que asciende a billones de dólares. ¿Alarmante, verdad?
Pero la magnitud de las consecuencias ha aumentado significativamente, especialmente en el mundo de la IA Generativa (GenAI).
Pero, ¿qué es GenAI? Según la investigación de IBM, “GenAI se refiere a modelos de aprendizaje profundo que pueden generar texto, imágenes y otro contenido de alta calidad basado en los datos con los que fueron entrenados.”
Al hablar de GenAI, la discusión sobre los Modelos de Lenguaje Grande (LLMs) se vuelve inevitable. Los LLMs, como la arquitectura GPT-4 que impulsa a ChatGPT, son ejemplos de IA generativa. Se entrenan con enormes cantidades de texto de internet, libros, artículos y otras fuentes para aprender los patrones estadísticos y estructuras del lenguaje.
Han cambiado el panorama de la IA, destacando la importancia de los datos de buena calidad como nunca antes. Ya sea en los chatbots cotidianos o en aplicaciones avanzadas que integran LLMs, la calidad de los datos ha adquirido una énfasis sin precedentes. Se ha convertido en un requisito básico para las organizaciones que buscan aprovechar el poder de GenAI y, por lo tanto, es el foco de nuestro blog.
El impacto de los datos de mala calidad en el entrenamiento de LLMs
Una de las razones detrás de la “amplitud” de los LLMs es que se entrenan con un gran corpus de datos recopilados de diversas fuentes. El modelo depende de la calidad de estos grandes conjuntos de datos para aprender las complejidades de los patrones del lenguaje y generar respuestas coherentes en consecuencia.
Sin embargo, los datos de mala calidad en forma de inexactitudes o registros de datos erróneos tienden a introducir ruido en el entrenamiento del modelo, lo que es muy perjudicial. Estos datos ruidosos obstaculizan la capacidad del modelo para comprender y generar contextos precisos y significativos, lo que afecta la calidad de sus resultados.
Más datos, más caos
Por la misma construcción del proceso de aprendizaje automático, a los modelos se les muestran numerosos ejemplos para generalizar en datos nuevos y no vistos. Del mismo modo, los LLMs aprenden de los patrones subyacentes en los datos del lenguaje para generar respuestas basadas en texto a diferentes entradas.
Pero si el modelo ha recibido datos de mala calidad, no puede entender o responder adecuadamente a ciertas entradas o genera respuestas absurdas o engañosas. Esto puede erosionar la confianza del usuario y limitar la utilidad práctica del modelo, una preocupación que se escucha con frecuencia en la comunidad de IA.
El costo de los datos de mala calidad es demasiado alto para los LLMs
En este punto, hemos llegado a comprender el impacto sustancial de los datos de mala calidad en el proceso de aprendizaje de patrones y la confiabilidad de los LLMs. Sin embargo, lo que es aún más preocupante es el costo que acompaña cuando estos datos infiltran el entrenamiento de los modelos LLM.
Examinemos por qué este costo es motivo de preocupación.
El entrenamiento de estos modelos grandes se sabe que requiere recursos informáticos y energéticos significativos. Por lo tanto, se vuelve imperativo no gastar energía permitiendo que el modelo aprenda a partir de registros ruidosos o erróneos.
Además, no se limita solo a la utilización de recursos informáticos. La naturaleza iterativa de este proceso resulta en retrasos significativos en el desarrollo del modelo, lo que posteriormente contribuye al costo general del desarrollo del modelo.
Para poner en perspectiva la escala de costos, un modelo de 530 mil millones de parámetros costaría aproximadamente 100 millones de dólares en volver a entrenarlo. Ciertamente, nadie querría gastar un costo tan exorbitante por permitir que los datos de mala calidad pasen desapercibidos.
La validación y verificación de la calidad de datos son críticas para construir modelos de aprendizaje automático exitosos. Sin embargo, cuando se trata específicamente de entrenar LLMs, el impacto de la mala calidad de los datos aumenta sustancialmente debido a la escala y complejidad del proceso de entrenamiento, lo que hace aún más importante comprender los efectos adversos significativos que pueden surgir.
OpenAI también ha expresado preocupaciones sobre hacer que el modelo olvide los datos malos, reflejando el papel de los datos de calidad.
Practica el “Shift-Left”
Implementar controles de monitoreo de datos directamente en el nivel de origen no solo es una mejor práctica, sino también un enfoque proactivo para preservar la calidad de los datos. Actúa como una medida de ahorro de costos, eliminando la necesidad de volver a entrenar el modelo debido a preocupaciones sobre la calidad de los datos que pueden surgir más tarde.
Abordar estas preocupaciones desde el principio puede minimizar la necesidad de volver a entrenar modelos costosos. Cuanto más tiempo persistan los problemas de calidad de datos, más costosos se vuelven para una organización. Para mitigar esto, es crucial cambiar el enfoque de la calidad de datos lejos de los consumidores finales hacia su origen, adoptando un enfoque de “shift-left”.
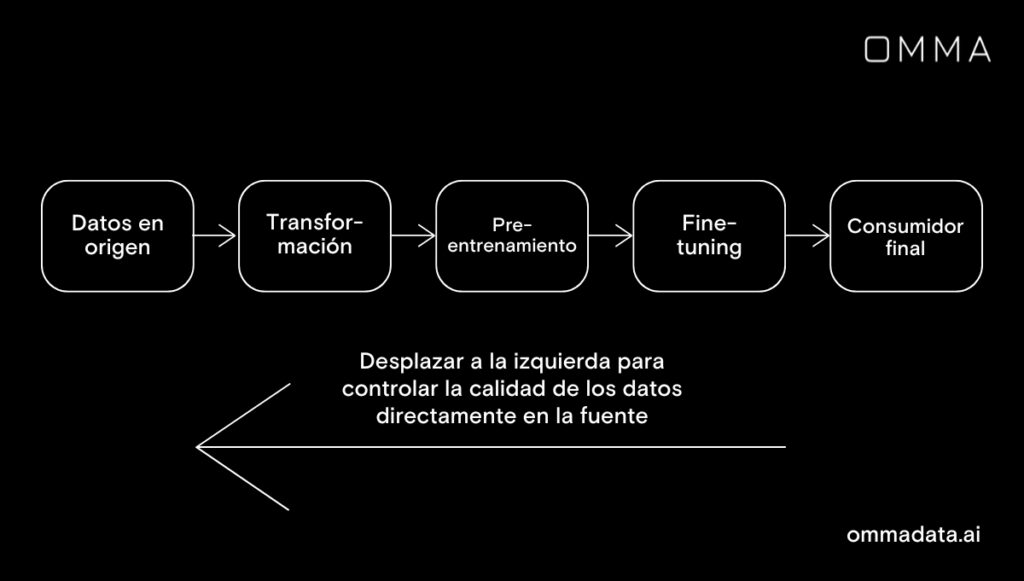
Además del costo tangible, el retraso en actuar sobre la calidad de los datos implica un sobrecosto de supervisión humana, que es responsable de evaluar y validar los resultados del modelo y proporcionar retroalimentación para mejorar el rendimiento del modelo. Inevitablemente, se pierde mucho tiempo antes de abordar estas preocupaciones a través de este ciclo de retroalimentación.
No se obtienen buenos datos por defecto — hay que crearlos
Un escenario ideal sería modelar el fenómeno o aprender el patrón a partir de datos bien curados, pero no obtenemos datos ideales en el mundo real. Entonces, entremos en un mundo realista donde los datos pueden tener prácticamente todo tipo de problemas y necesitan atención en todas sus múltiples dimensiones, como precisión, confiabilidad, integridad, relevancia, etc.
Se requiere un extenso preprocesamiento de datos como la eliminación de duplicados, corrección de ortografía y gramática, detección de valores atípicos y filtrado de contenido irrelevante o de baja calidad. Analizar los datos en mayor detalle incluye comprobaciones, incluyendo pero no limitadas a identificar — qué valores puede contener un campo, los tipos de datos esperados, cómo es el esquema, la definición de un registro atípico, etc.
Los datos cambian de forma y estructura en cada interacción y requieren una evaluación de la transformación de datos prevista versus real. Existen varias reglas que abarcan conocimiento empresarial, distribuciones de datos, tipos de campo, etc., junto con las mejores prácticas para implementarlas de manera efectiva.
Si bien algunas reglas estáticas son ciertamente útiles, rápidamente encuentran limitaciones al tratar con datos a gran escala para entrenar LLMs. Además, es importante destacar que el monitoreo manual es propenso a errores humanos, lo que genera la necesidad de controles automatizados de calidad a escala.
Además, estos controles automáticos alertan a las partes interesadas en tiempo real, lo que facilita el monitoreo y corrección continuos, convirtiéndolo en un enfoque de ciclo de vida en lugar de una iniciativa de “arreglar todo de una vez”.
Resumen
La principal preocupación entre los ejecutivos es la falta de confianza en los datos en los que se basan las ideas. Los LLMs ya son costosos de entrenar desde el principio, y la necesidad de volver a entrenar debido a datos de mala calidad sería nada menos que una pesadilla. Por lo tanto, es imperativo trabajar en todos los aspectos de la calidad de datos para descubrir el potencial de los LLMs y los modelos de aprendizaje automático.
Para mejorar el retorno de la inversión (ROI) para cualquier iniciativa de datos, independientemente del tamaño de los conjuntos de datos que alimentan los modelos GenAI, una evaluación exhaustiva de la calidad de los datos es absolutamente necesaria.

